
In a previous blog post, I’d described how instance NUMA topologies and CPU pinning worked in the OpenStack Compute service (nova). Starting with the 20.0.0 (Train) release, things have changed somewhat. This post serves to explain how things have changed and what impact that will have on a typical deployment.
The pre-Train world
As noted previously, a NUMA topology could be added to an instance either
explicitly, using the hw:numa_nodes=N flavor extra spec, or implicitly, by
requesting a specific mempage size (hw:mem_page_size=N) or CPU pinning
(hw:cpu_policy=dedicated). For historical reasons, it is not possible to
request memory pages or CPU pinning without getting a NUMA topology meaning
every pinned instance or instance with hugepages (common when using something
like Open vSwitch with DPDK) has a NUMA topology associated with it.
The presence of a NUMA topology implies a couple of things. The most beneficial of them is that each instance NUMA node is mapped to a unique host NUMA node and will only consume CPUs and RAM from that host node. The NUMA topology of the instance is exposed to the guest OS meaning well engineered applications running in the guest OS are able to able to tune themselves for this topology and avoid cross-NUMA node memory accesses and the performance penalties these brings. Unfortunately, there have also been some downsides, of which two were rather significant. The most impactful of these was the inability to correctly live migrate such instances, as noted in bug #1417667. In short, that bug noted that nova was not recalculating any of its CPU or mempage pinning information on a migration, resulting in a failure to live migrate to hosts with different NUMA topologies or, worse, individual instance NUMA nodes being spread across multiple NUMA nodes or the pinned CPUs of pinned instances overlapping with those of other pinned instances. The other issue stemmed from nova’s schizophrenic model for tracking resource utilization, where it used different models for tracking pinned CPUs from unpinned or “floating” CPUs, along with different models for tracking standard memory from explicit small and huge page requests. Combined, these led to a scenario where operators had to divide their datacenters up into host aggregates in order to separate normal, unpinned instances from both pinned instances and unpinned instances with a NUMA topology.
Train to the rescue
Train changes things. Not only does it resolve the live migration issue through
the completion of the NUMA-aware live migration spec but it introduces an
entirely new model for tracking CPU resources that prevents the need to
shard your datacenter using host aggregates. This is made possible by the
reporting of a new resource type, PCPU, for host CPUs intended to host pinned
instance CPUs. This is described in the Train release notes.
Compute nodes using the libvirt driver can now report
PCPUinventory. This is consumed by instances with dedicated (pinned) CPUs. This can be configured using the[compute] cpu_dedicated_setconfig option. The scheduler will automatically translate the legacyhw:cpu_policyflavor extra spec orhw_cpu_policyimage metadata property toPCPUrequests, falling back toVCPUrequests only if noPCPUcandidates are found. Refer to the help text of the[compute] cpu_dedicated_set,[compute] cpu_shared_setandvcpu_pin_setconfig options for more information.
We’ll explore how this manifests itself in a bit, but before that we should
look at how one can migrate from an existing pre-Train deployment using
[DEFAULT] vcpu_pin_set (or not using it, as the case may be) to these new
configuration options.
Migrating to Train
The migration from Stein to Train is tricky. In short, we need to migrate from
[DEFAULT] vcpu_pin_set to a combination of [compute] cpu_shared_set and
[compute] cpu_dedicated_set and unset [DEFAULT] reserved_host_cpus. How you
do this is touched upon in the help text for the [DEFAULT] vcpu_pin_set,
[compute] cpu_shared_set and [compute] cpu_dedicated_set options.
As always, a diagram will help:
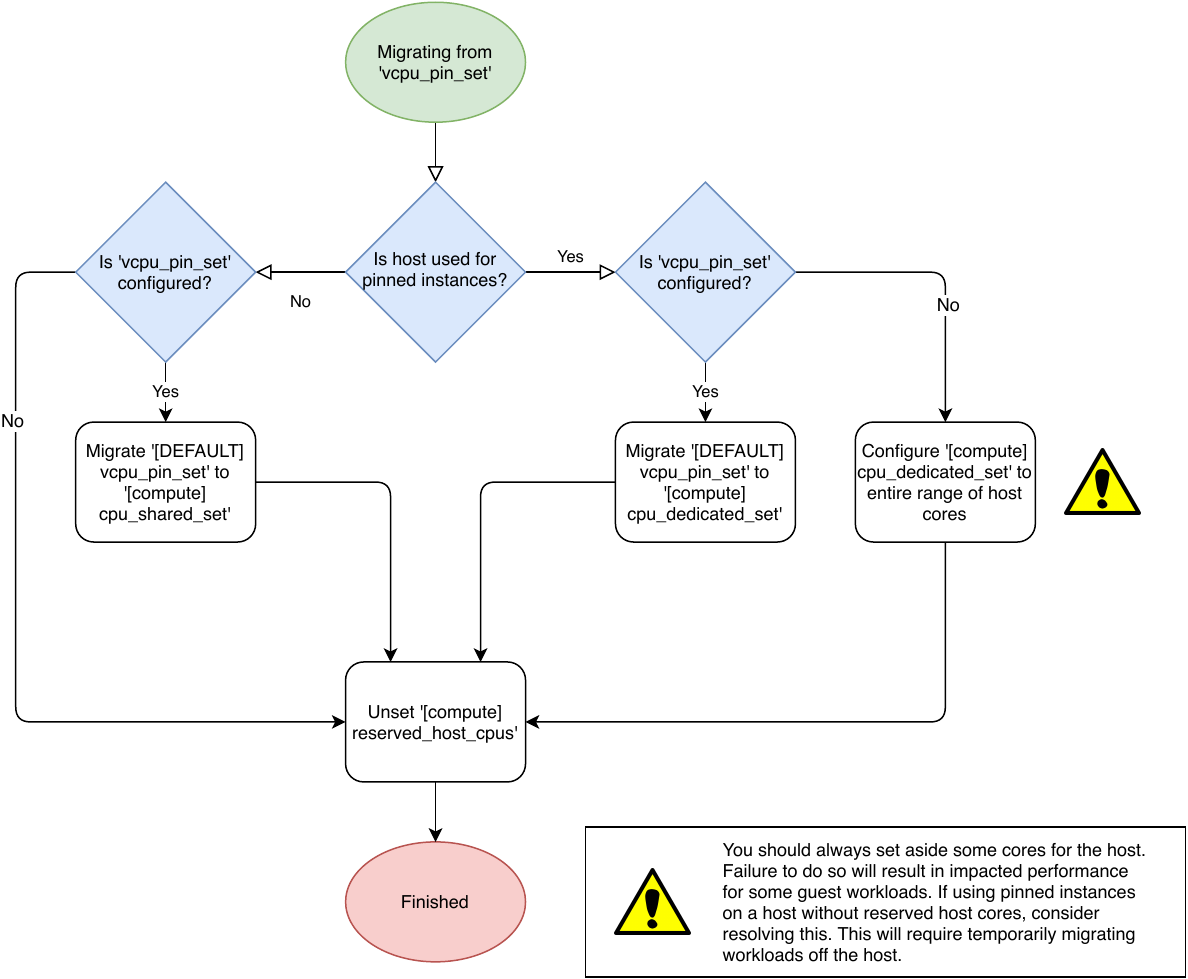
Once this migration is complete, restarting the nova-compute service will
result in nova automatically “reshaping” the inventory for the compute node
stored in placement. Any host CPUs listed in the [compute] cpu_shared_set
config option will continue to be reported as VCPU inventory, but host CPUs
listed in the [compute] cpu_dedicated_set config option will be reported as
PCU inventory.
Examples
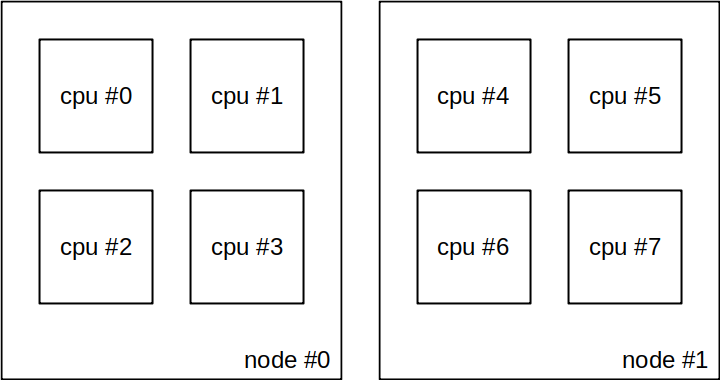
Let’s look at some examples of how this would be reflected in the real world. For all these examples, consider a host with two sockets and two CPUs with four cores and no hyperthreading (so eight CPUs).
Hosts with unpinned workloads
If your host is only intended for unpinned workloads, you don’t need to do
anything! If neither [compute] cpu_shared_set nor [compute] cpu_dedicated_set are configured, the former will default to all host cores.
We can see this in practice by examining the placement records for the given compute node. For example:
$ openstack --os-placement-api-version 1.18 resource provider inventory show \
6a969900-bbf7-4725-959b-2db3092933b0 VCPU
+------------------+-------+
| Field | Value |
+------------------+-------+
| allocation_ratio | 16.0 |
| max_unit | 8 |
| reserved | 0 |
| step_size | 1 |
| min_unit | 1 |
| total | 8 |
+------------------+-------+
$ openstack --os-placement-api-version 1.18 resource provider inventory show \
6a969900-bbf7-4725-959b-2db3092933b0 PCPU
Optionally, we might decide to exclude a certain number of cores, perhaps
setting aside some for the host. For example, to reserve core 0 from each host
NUMA node for the host, configure the following in nova.conf:
[compute]
cpu_shared_set = 1-3,5-7
If we now query placement again, we’ll see the number of available VCPU
inventory has dropped.
$ openstack --os-placement-api-version 1.18 resource provider inventory show \
6a969900-bbf7-4725-959b-2db3092933b0 VCPU
+------------------+-------+
| Field | Value |
+------------------+-------+
| allocation_ratio | 16.0 |
| max_unit | 6 |
| reserved | 0 |
| step_size | 1 |
| min_unit | 1 |
| total | 6 |
+------------------+-------+
$ openstack --os-placement-api-version 1.18 resource provider inventory show \
6a969900-bbf7-4725-959b-2db3092933b0 PCPU
Hosts with pinned workloads
Next, let’s consider a host that’s only intended for pinned workloads.
Previously, we highly recommended configuring [DEFAULT] vcpu_pin_set as not
setting this could result in impacted performance for some workloads due to
contention from the host. The new [compute] cpu_dedicated_set option is
mandatory because, as noted above, not configuring any option will result in
all host cores being reported as VCPU inventory. Let’s once again reserve
core 0 from each host NUMA node for the host by configuring our nova.conf
like so:
[compute]
cpu_dedicated_set = 1-3,5-7
If we query placement, we’ll no longer see VCPU inventory but rather PCPU
inventory.
$ openstack --os-placement-api-version 1.18 resource provider inventory show \
6a969900-bbf7-4725-959b-2db3092933b0 VCPU
$ openstack --os-placement-api-version 1.18 resource provider inventory show \
6a969900-bbf7-4725-959b-2db3092933b0 PCPU
+------------------+-------+
| Field | Value |
+------------------+-------+
| allocation_ratio | 1.0 |
| max_unit | 6 |
| reserved | 0 |
| step_size | 1 |
| min_unit | 1 |
| total | 6 |
+------------------+-------+
Hosts with mixed pinned and unpinned workloads
Finally, let’s consider a host with both pinned and unpinned workloads. As
discussed earlier, this was not previously possible. To do this, we must simple
configure both [compute] cpu_shared_set and [compute] cpu_dedicated_set on
the host. Given that we have two host NUMA nodes with for cores per node, let’s
reserve two cores from each node for both pinned and unpinned workloads by
configuring our nova.conf like so:
[compute]
cpu_shared_set = 0,1,4,5
cpu_dedicated_set = 2,3,6,7
If we query placement, we’ll now see both VCPU and PCPU inventory reported
alongside each other.
$ openstack --os-placement-api-version 1.18 resource provider inventory show \
6a969900-bbf7-4725-959b-2db3092933b0 VCPU
+------------------+-------+
| Field | Value |
+------------------+-------+
| allocation_ratio | 16.0 |
| max_unit | 4 |
| reserved | 0 |
| step_size | 1 |
| min_unit | 1 |
| total | 4 |
+------------------+-------+
$ openstack --os-placement-api-version 1.18 resource provider inventory show \
6a969900-bbf7-4725-959b-2db3092933b0 PCPU
+------------------+-------+
| Field | Value |
+------------------+-------+
| allocation_ratio | 1.0 |
| max_unit | 4 |
| reserved | 0 |
| step_size | 1 |
| min_unit | 1 |
| total | 4 |
+------------------+-------+
Summary
The ability to place both pinned and unpinned instances on the same compute node should lead to higher resource utilization and avoid the need to shard your compute, both of which are very useful features for smaller deployments.