
Next Friday is the last week of this stint at Intel, so I figured now was as good a time as ever to do a write up on how I work, or, more accurately, how I’ve worked, during my time here. Note that this has evolved massively over the past three years, so expect what I say now to have changed significantly a year down the line.
At the moment, I work predominantly on nova, though I contribute to many other projects like openstack-manuals, oslo.config, DevStack and Patchwork. Not all of these projects are OpenStack projects, but they are all Python-based, meaning the development environments for each tend to be rather similar.
Platform
First up - my development platform. My current work laptop is a tad bit…under-resourced (think: 4GB of RAM) and is Windows-based, meaning I always end up working on remote machines via SSH (more on that later). The remote machines I use vary depending on what I want to do. Most of the time I use a handful of VMs provided via an internal cloud. These provide me with a shared home directory (so I don’t have to configure Vim each time I start using a new VM, heh) and some flexibility for things like basic multi-node testing. However, when I need to validate features on real hardware (which happens quite regularly, given the areas I’m working on), I’ll use some real hardware from the lab. These platforms are the kind of platforms you’ll find in every good data center around the world: multiple top-of-the-line Xeon E5s, super-fast NVMe SSD storage, the latest Intel NICs (SR-IOV compatible, of course) and many, many GBs of RAM.
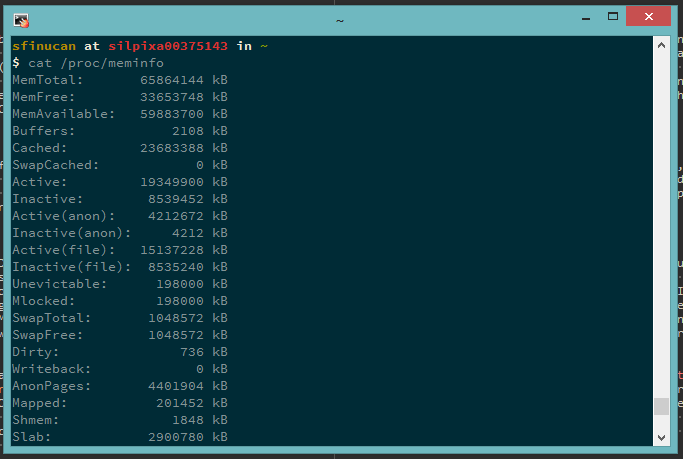
That's a lot of RAM
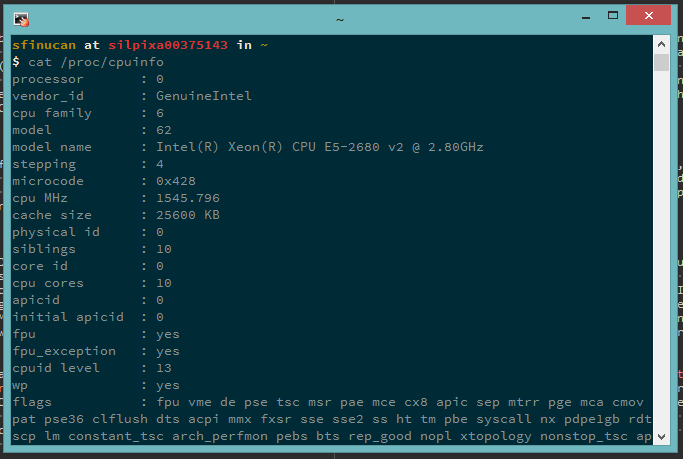
One of many cores
Environment
While the hardware of the platforms I use does vary tremendously, the software environments are remarkably consistent. To start, everything runs whatever the latest version of Fedora happens to be - while Ubuntu may be currently the most popular platform to deploy OpenStack on, I’ve used Fedora at home for years and saw no reason to switch. On top of this, I either deploy OpenStack using DevStack, if I want to validate a feature, or I simply clone and work on the project repos directly, if I’m working or unit-testable code or “low-hanging-fruit” tasks. Finally, where required, I pre-configure my tools using the configuration files provided by my dotfiles project.
I work on a lot of projects
Tooling
Tooling makes or breaks developers: learning what tools to use, and when, is an important part of any developers own development. I know a lot of people who use IDEs like PyCharm (indeed, you can get a free community license if you contribute to OpenStack), but seeing as I don’t develop on my local machine, I need to use some form of remote rendering - VNC, X11 forwarding, RDP - for the IDE GUI, I need to configure a remote mount so that a local installed IDE could access files on my remote machines. I’ve found both of these options to perform poorly over bad connections and result in either a janky, laggy UI or an inability to do things like change branches with any regularity, respectively. Annoying, to say the least.
As a result of the above, I’ve been slowly dropping GUI-based tools from my toolkit over the years. The largest change here was my replacment of Sublime Text and its plugins with Vim and plugins managed by Vundle (delighted not to be writing plugins for Vim, tbh). In addition to this change, I also dropped Meld, which was pretty but laggy over X11 forwarding, in favor of the more responsive ConflictMarker Vim plugin (I’m yet to grasp Vimdiff). Similarly, I’ve replaced MTPuTTY and its multiple tabs with standard PuTTY and tmux. All these tools do have an additional learning curve over their GUI-driven equivalents, but they’re all battle-tested, incredibly efficient, and work well on pretty much any type of network connection.
I use Vim extensively
Outside of these tools, I also make extensive use of git-review
and ag (a.k.a. the silver searcher). git-review allows me to quickly
submit my own changes for community review or download other peoples’ changes
for validation, and it is the tool the OpenStack community recommends for
working with Gerrit-based projects. ag, on the other hand, is my way of
handling the lack of an IntelliSense-like feature in Vim. It’s a faster version
of awk that also takes things like gitignore files into account. I use this
to search for function calls etc. I plan to eventually try something like
Jedi but I just haven’t got around to this yet.
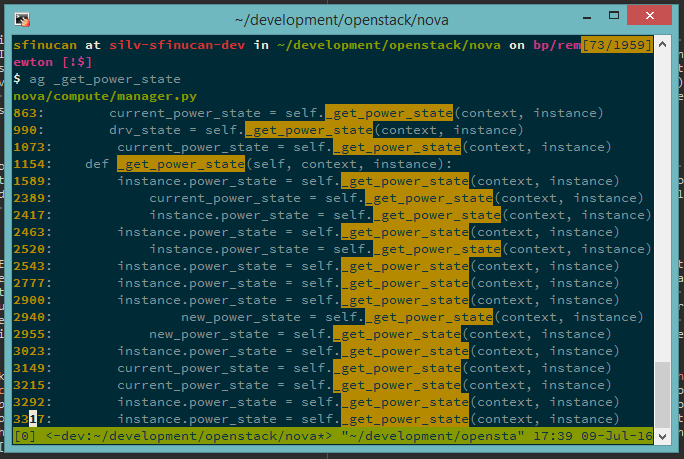
ag is fast and pretty
Finally, debugging, where necessary, is possible through pdb and the odd post to the mailing list is made using mutt. pdb, like many of these tools, does take a bit of time to get your head around, but, once up and running, proves itself worth the effort. mutt has a similarly large learning curve, but it doesn’t mess up the formatting of emails half as bad as Outlook and its threading actually works.
Future Plans
There are a couple of tools that have been recommended to me, that I just haven’t got around to trying yet.
- git-next: Developed by the awesome Dolph Matthews, this simple tool should be configured with your favourite OpenStack project. Once done, you can run it provide you with the next patch that you should review.
- gertty: This is another OpenStack-provided project. This tool provides a CLI for Gerrit tool, and allows you to do things like review code offline. The latter feature isn’t so useful when working remotely all the time, but if/when I start developing locally, I’ll be sure to use this.
- Jedi: As mentioned above, how I navigate the code base could do with a bit of work. Jedi brings autocomplete and some other stuff to editors like Vim.
- PyCharm: This is another one to throw in the “if I ever develop locally” bag. I don’t use this now, but if it becomes an option then I’ll definitely try it. I do wish the open source alternatives weren’t quite so…Java’y though.
- ???: Who knows what else I’ll discover in the coming years?
Bonus: SSH Configuration
How I actually connect to the machines is probably worth calling out also. For this, I use the PuTTY family of tools. To begin with, I have PuTTYTray installed and pinned to my taskbar to enable quick access to some tools in the suite (PuTTY, Pageant, PuTTYGen).
PuTTYTray in action
The out-of-the-box experience for PuTTY itself is rather poor, so I rely on the Solarized Modern PuTTY Defaults project to bring things into the 21st century.
Pretty colours. Not so pretty test results.
I don’t fancy typing in a password each time, so I generate SSH keys using Pageant, then I make sure Pageant starts automatically each time I boot my machine. I’ll probably do a more in-depth write up of this process at some point.