
This is the blog form of a talk I delivered at PyCon Ireland 2022. You can find the slides here and the source code here.
One thing to note before we begin is that while I mention OpenStack services below, this article isn’t actually about OpenStack 😉 We’re merely using it as a good example. The problems that OpenStack needs to address such as scaling out services in larger deployments are common to most distributed services.
Background
In the beginning, there were only two OpenStack services: Swift, which was responsible for object-storage, and Nova, which handled everything else. Over time, the list of services has grown enormously as Nova has shed some of its former responsibilities to other services and the amounts of things an OpenStack cloud can do has grown. However, due to many projects’ shared heritage (where they were split out from or modeled on Nova) and general design decisions made in the early days of OpenStack, even the newest OpenStack services tend to have a couple of commonalities in their design. Two of these are relevant to this article. Firstly, many of the services are designed to be horizontally scalable and almost always use a message broker to achieve this. This message broker is typically RabbitMQ and it provides a way for multiple instances of a service to communicate with each other. Secondly, without fail, OpenStack services will use a traditional relational DB to store data. The database backend is usually MySQL (although PostgreSQL is also an option) while SQLAlchemy is used for them ORM.
These two design decisions are relevant because they contain an inherent conflict. There can be many instances of a service (e.g. nova-conductor or nova-api) but they will all share a single database. If the schema of the database changes then each of these services will need to understand the new format. Historically in OpenStack, the way to do this was to closely couple the source code and database schema. An upgrade to a new version of OpenStack would necessitate taking all services down, upgrading the service code and the database schema, and then restarting the services. It works but it requires potentially large API downtime: the table lock that MySQL grabs while migrating the schema will block all reads and writes until the migration is complete, and for large installations where tables can have many millions of rows that migration can take minutes if not hours. This isn’t good enough for most production enterprise clouds, let alone specific applications like Telco where SLAs are something that the government cares about. What we want is the ability to do rolling upgrades. Enter expand-contract.
The Expand-Migrate-Contract pattern
We can start exploring the expand-contract pattern by thinking about what happens to the data in an application during a migration.
- Data can be added. For example, adding a new
namefield to a user account model. - Data can change. For example, combining separate existing
first_nameandlast_namefields into a singlenamefield. - Data can be deleted. For example, dropping the old
first_nameandlast_namefields.
The basic idea behind the expand-migrate-contract migration pattern is to split the schema migrations into two groups: additive changes, which will handle the added data, and contractive/destructive changes, which will handle the removed data. The changed data is an example of a data migration and either the application or another set of migrations handles this. If you’re a visual person, you can visualize this like so:
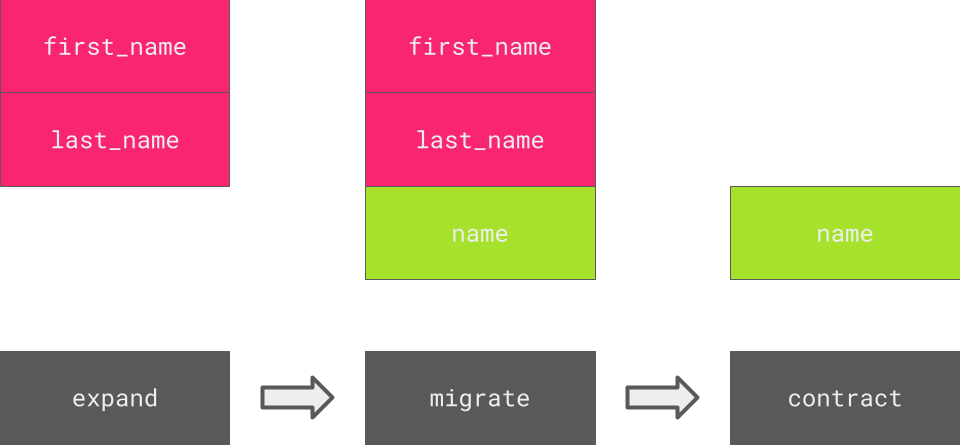
A visualization of expand-migrate-contract
By applying the expand-contract migration, we can move from an upgrade pattern like this:
- Stop all services
- Upgrade the services and apply all database schema migrations.
- Wait X minutes/hours/days for the schema migration to complete.
- Restart all services
To this:
- Apply the “expand” database schema migration
- Upgrade the service instances one-by-one until all services have been upgraded
- (Optional) Apply database data migrations
- (At some future point) Apply the “contract” database schema migrations
There are often a couple of additional steps that your application will need to do, but the basic idea here is that by adapting the expand-migrate-contract pattern in your application, you can both allow your database schema to evolve while avoiding undesirable downtime.
Now that we have all this background out of the way, where do Alembic and SQLAlchemy fit into this equation? I’m glad you asked!
Initial steps
So before we start talking about alternative database upgrade plans, we need to have a platform to build on. To this end, let’s create an initial project structure and populate it with some initial SQLAlchemy models. I’ve based this on a slightly modified version of the sample models found in the SQLAlchemy quick start guide.
❯ mkdir -p alembic-expand-contract-demo/alembic_expand_contract_demo
❯ cd alembic-expand-contract-demo
❯ touch alembic_expand_contract_demo/__init__.py alembic_expand_contract_demo/models.py alembic_expand_contract_demo/README.md
Dump the following into the newly created alembic_expand_contract_demo/models.py file:
from sqlalchemy import Column
from sqlalchemy import ForeignKey
from sqlalchemy import Integer
from sqlalchemy import String
from sqlalchemy.orm import declarative_base
from sqlalchemy.orm import relationship
Base = declarative_base()
class User(Base):
__tablename__ = "user_account"
id = Column(Integer, primary_key=True)
first_name = Column(String(30))
last_name = Column(String(30))
addresses = relationship(
"Address", back_populates="user", cascade="all, delete-orphan"
)
def __repr__(self):
return f"User(id={self.id!r})"
class Address(Base):
__tablename__ = "address"
id = Column(Integer, primary_key=True)
email_address = Column(String, nullable=False)
user_id = Column(Integer, ForeignKey("user_account.id"), nullable=False)
user = relationship("User", back_populates="addresses")
def __repr__(self):
return f"Address(id={self.id!r})"
We’ll also create our requirements.txt file and install those requirements.
❯ cat > requirements.txt << EOF
sqlalchemy
alembic
EOF
❯(.venv) virtualenv .venv
❯(.venv) source .venv/bin/activate
❯(.venv) pip install -r requirements.txt
With our initial models in place, we can now proceed to creating the initial migration directory structure.
❯(.venv) alembic init alembic_expand_contract_demo/migrations
You should now have a directory structure like so:
.
├── alembic_expand_contract_demo
│ ├── __init__.py
│ ├── migrations
│ │ ├── env.py
│ │ ├── README
│ │ ├── script.py.mako
│ │ └── versions
│ ├── models.py
├── alembic.ini
├── README.md
└── requirements.txt
As suggested by the wizard, you’ll want to make a few changes to the alembic.ini file created in the root of your directory. In particular, you’ll want to configure the [alembic] script_location and [alembic] sqlalchemy.url settings. I used the following:
[alembic]
script_location = %(here)s/alembic_expand_contract_demo/migrations
sqlalchemy.url = sqlite:///alembic-expand-contract-demo.db
You’ll also need to configure the env.py file found in the new alembic_expand_contract_demo/migrations directory to point the target_metadata value to your base model. For example:
from alembic_expand_contract_demo import models
# ...
target_metadata = models.Base.metadata
Finally, we’ll modify the migration script template script.py.mako in the alembic_expand_contract_demo/migrations directory to remove the downgrade step: downgrades aren’t all that useful in a production environment (back up your data!) and add needless complexity here:
--- alembic_expand_contract_demo/migrations/script.py.mako
+++ alembic_expand_contract_demo/migrations/script.py.mako
@@ -2,9 +2,8 @@
Revision ID: ${up_revision}
Revises: ${down_revision | comma,n}
-Create Date: ${create_date}
-
"""
+
from alembic import op
import sqlalchemy as sa
${imports if imports else ""}
@@ -18,7 +17,3 @@ depends_on = ${repr(depends_on)}
def upgrade() -> None:
${upgrades if upgrades else "pass"}
-
-
-def downgrade() -> None:
- ${downgrades if downgrades else "pass"}
With all this in place, we can now create an initial empty database and generate our first migration (Alembic needs a database to compare against to generate the updated schema).
❯ alembic upgrade head
Once this is run, you’ll note a new alembic-expand-contract-demo.db SQLite database in your root directory. A quick look at the schema of this database shows an effectively empty table with only Alembic’s own alembic_version table present. This is expected: while we have models in place, we don’t yet have a Alembic migration to add them.
❯ sqlite3 alembic-expand-contract-demo.db '.dump'
PRAGMA foreign_keys=OFF;
BEGIN TRANSACTION;
CREATE TABLE alembic_version (
version_num VARCHAR(32) NOT NULL,
CONSTRAINT alembic_version_pkc PRIMARY KEY (version_num)
);
COMMIT;
Since we’d already wired everything up, we can now simply run the revision sub-command with the --autogenerate option and our migrations will be auto-generated:
❯ alembic revision --autogenerate --message='Initial models'
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.autogenerate.compare] Detected added table 'user_account'
INFO [alembic.autogenerate.compare] Detected added table 'address'
Generating /home/stephenfin/demos/alembic-expand-contract-demo/alembic_expand_contract_demo/migrations/versions/a185a7b16d70_initial_models.py ... done
This generates a migration that will look something like the following, once comments are addressed and formatting cleaned up:
"""Initial models
Revision ID: 6cb93d555e2b
Revises:
"""
from alembic import op
import sqlalchemy as sa
# revision identifiers, used by Alembic.
revision = '6cb93d555e2b'
down_revision = None
branch_labels = None
depends_on = None
def upgrade() -> None:
op.create_table(
'user_account',
sa.Column('id', sa.Integer(), nullable=False),
sa.Column('first_name', sa.String(length=30), nullable=True),
sa.Column('last_name', sa.String(length=30), nullable=True),
sa.PrimaryKeyConstraint('id'),
)
op.create_table(
'address',
sa.Column('id', sa.Integer(), nullable=False),
sa.Column('email_address', sa.String(), nullable=False),
sa.Column('user_id', sa.Integer(), nullable=False),
sa.ForeignKeyConstraint(
['user_id'],
['user_account.id'],
),
sa.PrimaryKeyConstraint('id'),
)
def downgrade() -> None:
op.drop_table('address')
op.drop_table('user_account')
Apply this and we should see the new tables in the database schema.
❯ alembic upgrade head
❯ sqlite3 alembic-expand-contract-demo.db '.dump'
PRAGMA foreign_keys=OFF;
BEGIN TRANSACTION;
CREATE TABLE alembic_version (
version_num VARCHAR(32) NOT NULL,
CONSTRAINT alembic_version_pkc PRIMARY KEY (version_num)
);
INSERT INTO alembic_version VALUES('6cb93d555e2b');
CREATE TABLE user_account (
id INTEGER NOT NULL,
first_name VARCHAR(30),
last_name VARCHAR(30),
PRIMARY KEY (id)
);
CREATE TABLE address (
id INTEGER NOT NULL,
email_address VARCHAR NOT NULL,
user_id INTEGER NOT NULL,
PRIMARY KEY (id),
FOREIGN KEY(user_id) REFERENCES user_account (id)
);
COMMIT;
Nothing complicated so far. Onto the meaty part.
First pass at expand-contract using Alembic
We now have an initial application. Time to start thinking about how to upgrade it. Looking at our models, we’ll note that we have separate first_name and last_name fields.
class User(Base):
__tablename__ = "user_account"
id = Column(Integer, primary_key=True)
first_name = Column(String(30))
last_name = Column(String(30))
addresses = relationship(
"Address", back_populates="user", cascade="all, delete-orphan"
)
def __repr__(self):
return f"User(id={self.id!r})"
Let’s say we wanted to merge these two fields into a single combined field called name. For example:
@@ -17,8 +17,7 @@ Base = declarative_base()
class User(Base):
__tablename__ = "user_account"
id = Column(Integer, primary_key=True)
- first_name = Column(String(30))
- last_name = Column(String(30))
+ name = Column(String)
addresses = relationship(
"Address", back_populates="user", cascade="all, delete-orphan"
)
We can auto-generate our migration once again:
❯ alembic revision --message='Merge user names'
This will give us a migration like so:
"""Merge user names
Revision ID: 0585005489f0
Revises: 6cb93d555e2b
"""
from alembic import op
import sqlalchemy as sa
# revision identifiers, used by Alembic.
revision = '0585005489f0'
down_revision = '6cb93d555e2b'
branch_labels = None
depends_on = None
def upgrade() -> None:
op.add_column(
'user_account', sa.Column('name', sa.String(), nullable=True)
)
op.drop_column('user_account', 'last_name')
op.drop_column('user_account', 'first_name')
def downgrade() -> None:
op.add_column(
'user_account',
sa.Column('first_name', sa.VARCHAR(length=30), nullable=True),
)
op.add_column(
'user_account',
sa.Column('last_name', sa.VARCHAR(length=30), nullable=True),
)
op.drop_column('user_account', 'name')
Clearly this isn’t very useful as it would result in data loss: we need to migrate data before we can remove the old column. The easy way to address this would be to modify the migration to also migrate data as an intermediary step. For example:
"""Merge user names
Revision ID: 0585005489f0
Revises: 6cb93d555e2b
"""
from alembic import op
import sqlalchemy as sa
# revision identifiers, used by Alembic.
revision = '0585005489f0'
down_revision = '6cb93d555e2b'
branch_labels = None
depends_on = None
def upgrade() -> None:
# schema migrations - expand
op.add_column(
'user_account',
sa.Column('name', sa.String(), nullable=True),
)
# data migrations
bind = op.get_bind()
user_account_table = sa.Table(
'user_account',
sa.MetaData(),
sa.Column('id', sa.Integer(), nullable=False),
sa.Column('first_name', sa.String(length=30), nullable=True),
sa.Column('last_name', sa.String(length=30), nullable=True),
sa.Column('name', sa.String, nullable=True),
)
names = bind.execute(
sa.select(
[
user_account_table.c.id,
user_account_table.c.first_name,
user_account_table.c.last_name,
]
)
).fetchall()
for id, first_name, last_name in names:
bind.execute(
user_account_table.update()
.where(user_account_table.c.id == id)
.values(
name=f'{first_name} {last_name}',
)
)
# schema migrations - contract
op.drop_column('user_account', 'first_name')
op.drop_column('user_account', 'last_name')
def downgrade() -> None:
raise Exception("Irreversible migration")
While this works, as noted at the outset this approach doesn’t work for scaled applications or applications with uptime guarantees: your applications would need to be taken offline while this database schema was applied, which itself is an operation that could take some time. Let’s try an expand-contract approach instead. First, we’ll do this manually. Instead of having one large migration file, we’ll create three separate migration files (or two, if your application is going to take care of data migrations at runtime).
❯ alembic revision --message='Merge user names (expand)'
❯ alembic revision --message='Merge user names (migrate)'
❯ alembic revision --message='Merge user names (contract)'
In the “expand” migration, we add the new column:
"""Merge user names (expand)
Revision ID: 9c36df1b3f62
Revises: 6cb93d555e2b
"""
from alembic import op
import sqlalchemy as sa
# revision identifiers, used by Alembic.
revision = '9c36df1b3f62'
down_revision = '6cb93d555e2b'
branch_labels = None
depends_on = None
def upgrade() -> None:
op.add_column(
'user_account',
sa.Column('name', sa.String(), nullable=True),
)
In the “migrate” migration, we migrate our data:
"""Merge user names (migrate)
Revision ID: c9afc30a70ee
Revises: 9c36df1b3f62
"""
from alembic import op
import sqlalchemy as sa
# revision identifiers, used by Alembic.
revision = 'c9afc30a70ee'
down_revision = '9c36df1b3f62'
branch_labels = None
depends_on = None
def upgrade() -> None:
# data migrations
bind = op.get_bind()
user_account_table = sa.Table(
'user_account',
sa.MetaData(),
sa.Column('id', sa.Integer(), nullable=False),
sa.Column('first_name', sa.String(length=30), nullable=True),
sa.Column('last_name', sa.String(length=30), nullable=True),
sa.Column('name', sa.String, nullable=True),
)
names = bind.execute(
sa.select(
[
user_account_table.c.id,
user_account_table.c.first_name,
user_account_table.c.last_name,
]
)
).fetchall()
for id, first_name, last_name in names:
bind.execute(
user_account_table.update()
.where(user_account_table.c.id == id)
.values(
name=f'{first_name} {last_name}',
)
)
Finally, in the “contract” migration, we remove the old columns:
"""Merge user names (contract)
Revision ID: e629a4ea0677
Revises: c9afc30a70ee
"""
from alembic import op
# revision identifiers, used by Alembic.
revision = 'e629a4ea0677'
down_revision = 'c9afc30a70ee'
branch_labels = None
depends_on = None
def upgrade() -> None:
# schema migrations - contract
op.drop_column('user_account', 'first_name')
op.drop_column('user_account', 'last_name')
This is better. However, it does mean you can’t simply run alembic upgrade head as this would apply all migrations in one go, totally defeating the point. What we want is a way to only apply the expand migrations initially, waiting to apply the other migrations later once all our services have been updated. This leads us to…
Branches
Per the Alembic docs:
A branch describes a point in a migration stream when two or more versions refer to the same parent migration as their ancestor.
They’re intended for scenarios where “two divergent source trees, both containing Alembic revision files created independently within those source trees, are merged together into one”. This could includes things like feature branches, where multiple developers are working on separate features and merge everything back in around the same time. However, we can also use them to separate our expand migrations from our contract migrations. Let’s look at how we’d do that. First the expand migration:
--- alembic_expand_contract_demo/migrations/versions/9c36df1b3f62_merge_user_names_expand.py
+++ alembic_expand_contract_demo/migrations/versions/9c36df1b3f62_merge_user_names_expand.py
@@ -11,7 +11,7 @@ import sqlalchemy as sa
# revision identifiers, used by Alembic.
revision = '9c36df1b3f62'
down_revision = '6cb93d555e2b'
-branch_labels = None
+branch_labels = ('expand',)
depends_on = None
All that we’ve done here is added a new expand branch label. Nothing odd there. Next up, the expand migration. As noted above, we’re actually going to skip this going forward since it’s not totally relevant, so let’s delete it and create a separate tool to manage the migrations.
❯ rm alembic_expand_contract_demo/migrations/versions/c9afc30a70ee_merge_user_names_migrate.py
❯ touch data-migration.py
# SPDX-License-Identifier: MIT
import sqlalchemy as sa
def migrate_data():
engine = sa.create_engine('sqlite:///alembic-expand-contract-demo.db')
user_account_table = sa.Table(
'user_account',
sa.MetaData(),
sa.Column('id', sa.Integer(), nullable=False),
sa.Column('first_name', sa.String(length=30), nullable=True),
sa.Column('last_name', sa.String(length=30), nullable=True),
sa.Column('name', sa.String, nullable=True),
)
with engine.connect() as conn:
names = conn.execute(
sa.select(
[
user_account_table.c.id,
user_account_table.c.first_name,
user_account_table.c.last_name,
]
)
).fetchall()
for id, first_name, last_name in names:
conn.execute(
user_account_table.update()
.where(user_account_table.c.id == id)
.values(
name=f'{first_name} {last_name}',
)
)
if __name__ == '__main__':
migrate_data()
Finally, the contract migration:
--- alembic_expand_contract_demo/migrations/versions/e629a4ea0677_merge_user_names_contract.py
+++ alembic_expand_contract_demo/migrations/versions/e629a4ea0677_merge_user_names_contract.py
@@ -9,8 +9,8 @@ from alembic import op
# revision identifiers, used by Alembic.
revision = 'e629a4ea0677'
-down_revision = 'c9afc30a70ee'
-branch_labels = None
+down_revision = '9c36df1b3f62'
+branch_labels = ('contract',)
depends_on = None
Again, nothing too odd here. We add the contract branch label and change the down revision to reflect the fact that we removed the data migration.
With these changes in place, we now have the ability to apply the branches separately.
❯ alembic upgrade expand
❯ python data-migration.py
❯ alembic upgrade contract
This is a further improvement from where we were, but we’re still missing a huge feature: auto-generation. While we can pass the --autogenerate flag alembic revision, the generated migrations need a lot of work including manually splitting the operations into expand and contract branch migrations. It would be great if Alembic could do this for us. Turns out it can, but it needs a bit of work.
Extending auto-generation to support expand-contract
What we need is a hook point to modify the migrations generated by Alembic so that we can separate them into expand migrations and contract migrations. To do this, Alembic provides process_revision_directives attribute to the context.configure API call found in env.py. From the Alembic docs:
process_revision_directives - a callable function that will be passed a structure representing the end result of an autogenerate or plain “revision” operation, which can be manipulated to affect how the alembic revision command ultimately outputs new revision scripts.
Before we configure that attribute, let’s create the callable function itself. To do this, we’re going to make use of the alembic.util.Dispatcher class. This is a class that is normally responsible for generating per-backend SQL statements for each migration operation. Instead of using this to generate SQL statements, we can use it to sift through the operations generated by Alembic so we can split them into two phases. Let’s look at how we can do this in practice. Create an new file, alembic_expand_contract_demo/migrations/autogen.py and dump the following into it. We’ll discuss the contents of the file step-by-step in a bit.
# SPDX-License-Identifier: MIT
from alembic.operations import ops
from alembic.util import Dispatcher
from alembic.util import rev_id as new_rev_id
_ec_dispatcher = Dispatcher()
def process_revision_directives(context, revision, directives):
directives[:] = list(_assign_directives(context, directives))
def _assign_directives(context, directives, phase=None):
for directive in directives:
decider = _ec_dispatcher.dispatch(directive)
if phase is None:
phases = ('expand', 'contract')
else:
phases = (phase,)
for phase in phases:
decided = decider(context, directive, phase)
if decided:
yield decided
@_ec_dispatcher.dispatch_for(ops.MigrationScript)
def _migration_script_ops(context, directive, phase):
op = ops.MigrationScript(
new_rev_id(),
ops.UpgradeOps(
ops=list(
_assign_directives(context, directive.upgrade_ops.ops, phase)
)
),
ops.DowngradeOps(ops=[]),
message=directive.message,
head=f'{phase}@head',
)
if not op.upgrade_ops.is_empty():
return op
@_ec_dispatcher.dispatch_for(ops.ModifyTableOps)
def _modify_table_ops(context, directive, phase):
op = ops.ModifyTableOps(
directive.table_name,
ops=list(_assign_directives(context, directive.ops, phase)),
schema=directive.schema,
)
if not op.is_empty():
return op
@_ec_dispatcher.dispatch_for(ops.AddConstraintOp)
@_ec_dispatcher.dispatch_for(ops.CreateIndexOp)
@_ec_dispatcher.dispatch_for(ops.CreateTableOp)
@_ec_dispatcher.dispatch_for(ops.AddColumnOp)
def _expands(context, directive, phase):
if phase == 'expand':
return directive
else:
return None
@_ec_dispatcher.dispatch_for(ops.DropConstraintOp)
@_ec_dispatcher.dispatch_for(ops.DropIndexOp)
@_ec_dispatcher.dispatch_for(ops.DropTableOp)
@_ec_dispatcher.dispatch_for(ops.DropColumnOp)
def _contracts(context, directive, phase):
if phase == 'contract':
return directive
else:
return None
@_ec_dispatcher.dispatch_for(ops.AlterColumnOp)
def _alter_column(context, directive, phase):
is_expand = phase == 'expand'
if is_expand and directive.modify_nullable is True:
return directive
elif not is_expand and directive.modify_nullable is False:
return directive
else:
raise NotImplementedError(
"Don't know if operation is an expand or contract at the moment: "
"%s" % directive
)
With that file in place, let’s take a look at what it’s doing. First, the process_revision_directives and _assign_directives functions:
_ec_dispatcher = Dispatcher()
def process_revision_directives(context, revision, directives):
directives[:] = list(_assign_directives(context, directives))
def _assign_directives(context, directives, phase=None):
for directive in directives:
decider = _ec_dispatcher.dispatch(directive)
if phase is None:
phases = ('expand', 'contract')
else:
phases = (phase,)
for phase in phases:
decided = decider(context, directive, phase)
if decided:
yield decided
Hopefully this should be mostly self-explanatory. process_revision_directives is initial “entry point” and all it does is overwrites the provided list of directives with our modified set. _assign_directives, on the other hand, does the bulk heavy lifting. It’s responsible for iterating through the generated directives calling the dispatcher for each phase that we’re examining.
Next, we look to look at the dispatchers themselves. For each type of operation, we need to write a separate dispatcher. The top-level operation is the generation of the migration script itself a.k.a. the MigrationScript operation. Let’s look at this first.
@_ec_dispatcher.dispatch_for(ops.MigrationScript)
def _migration_script_ops(context, directive, phase):
op = ops.MigrationScript(
new_rev_id(),
ops.UpgradeOps(
ops=list(
_assign_directives(context, directive.upgrade_ops.ops, phase)
)
),
ops.DowngradeOps(ops=[]),
message=directive.message,
head=f'{phase}@head',
)
if not op.upgrade_ops.is_empty():
return op
Again, hopefully there’s nothing too complicated. This dispatcher generates a migration script container a filtered list of upgrade directives (and no downgrade directives). This filtered list is filtered by phase, and we also specify a head that corresponds to the phase (expand@head for the expand phase).
Moving on, in addition to the MigrationScript operation, we have one other “meta” operation to concern ourselves with: ModifyTableOps. Fortunately, this isn’t too complicated. We basically ensure that all operations against a table are filtered by phase as we’d expect:
@_ec_dispatcher.dispatch_for(ops.ModifyTableOps)
def _modify_table_ops(context, directive, phase):
op = ops.ModifyTableOps(
directive.table_name,
ops=list(_assign_directives(context, directive.ops, phase)),
schema=directive.schema,
)
if not op.is_empty():
return op
Now for the first “real” operations: the expand operations. These are AddConstraintOp, CreateIndexOp, CreateTableOp, and AddColumnOp. Let’s look at the dispatcher for these.
@_ec_dispatcher.dispatch_for(ops.AddConstraintOp)
@_ec_dispatcher.dispatch_for(ops.CreateIndexOp)
@_ec_dispatcher.dispatch_for(ops.CreateTableOp)
@_ec_dispatcher.dispatch_for(ops.AddColumnOp)
def _expands(context, directive, phase):
if phase == 'expand':
return directive
else:
return None
Simply put, if we’re in expand phase and encounter one of these operations, proceed as normal. If we’re in the contract phase, skip it. As you’d imagine, the dispatcher for the contract options - DropConstraintOp, DropIndexOp, DropTableOp, and DropColumnOp - works pretty similarly:
@_ec_dispatcher.dispatch_for(ops.DropConstraintOp)
@_ec_dispatcher.dispatch_for(ops.DropIndexOp)
@_ec_dispatcher.dispatch_for(ops.DropTableOp)
@_ec_dispatcher.dispatch_for(ops.DropColumnOp)
def _contracts(context, directive, phase):
if phase == 'contract':
return directive
else:
return None
With the plain old create and destroy operations out of the way, we only have to take care of the remaining “modify” or “alter” operations. This consists of modifications to columns a.k.a. AlterColumnOp. The AlterColumnOp dispatcher is trickier that the others, so pay attention here:
@_ec_dispatcher.dispatch_for(ops.AlterColumnOp)
def _alter_column(context, directive, phase):
is_expand = phase == 'expand'
if is_expand and directive.modify_nullable is True:
return directive
elif not is_expand and directive.modify_nullable is False:
return directive
else:
raise NotImplementedError(
"Don't know if operation is an expand or contract at the moment: "
"%s" % directive
)
The only modification we support here is the modifying NULL constraints on columns. There are other modifications you can make, such as modifying the type or a server default but these operations should really involve a bit of manual intervention to handle correctly. What we’ve said here is that if we’re in the expand phase then settings a column to nullable is a-okay. Likewise, if we’re in the contract phase then setting a column to non-nullable is also permissible. All other cases are forbidden though and will raise a NotImplementedError exception.
With this in place, the final step is to enable the processor by passing the process_revision_directives argument to the context.configure API call in env.py:
--- alembic_expand_contract_demo/migrations/env.py
+++ alembic_expand_contract_demo/migrations/env.py
@@ -5,6 +5,7 @@ from sqlalchemy import engine_from_config
from sqlalchemy import pool
from alembic_expand_contract_demo import models
+from alembic_expand_contract_demo.migrations import autogen
# this is the Alembic Config object, which provides
# access to the values within the .ini file in use.
@@ -68,6 +69,7 @@ def run_migrations_online() -> None:
context.configure(
connection=connection,
target_metadata=target_metadata,
+ process_revision_directives=autogen.process_revision_directives,
)
with context.begin_transaction():
Testing things out
Now that we have all of our machinery in place, it’s time to take things for a spin. Let’s test out auto-generation using similar commands to those we used as the beginning of the article.
❯ alembic revision --autogenerate --message='Merge user names'
The first thing we notice is that there are no longer one but two generations generated. This looks promising and looking at the migrations themselves things look even better. First the expand migration:
❯ cat alembic_expand_contract_demo/migrations/versions/1630422c66fe_merge_user_names.py
"""Merge user names
Revision ID: 1630422c66fe
Revises: 9c36df1b3f62
"""
from alembic import op
import sqlalchemy as sa
# revision identifiers, used by Alembic.
revision = '1630422c66fe'
down_revision = '9c36df1b3f62'
branch_labels = None
depends_on = None
def upgrade() -> None:
op.add_column(
'user_account', sa.Column('name', sa.String(), nullable=True)
)
Now the contract migration:
❯ cat alembic_expand_contract_demo/migrations/versions/a142d030afc5_merge_user_names.py
"""Merge user names
Revision ID: a142d030afc5
Revises: e629a4ea0677
"""
from alembic import op
# revision identifiers, used by Alembic.
revision = 'a142d030afc5'
down_revision = 'e629a4ea0677'
branch_labels = None
depends_on = None
def upgrade() -> None:
op.drop_column('user_account', 'last_name')
op.drop_column('user_account', 'first_name')
Applying these works exactly as expected:
❯ alembic upgrade expand
❯ alembic upgrade contract
Hurrah, everything worked (hopefully)! However, this is only the first step. While this is a marked improvement on where we were, there are a few improvements we could yet make. For one, the names of the files don’t reveal information about whether a change is an expand or contract migration. You can figure this out by looking at the migrations themselves but it would be much nicer if we could somehow indicate this through the filenames or, better yet, by separating them into separate folders. The branches here are also long-running and it would be nice if we could apply, say, all expand migrations up to a specific release along with any contract migrations from the previous release (which should be okay to apply assuming you’ve upgraded all services to the previous release version and have been running it for some time to migrate data). Both of these requests (and more!) can be achieved, but that’s outside the scope of this article. I’d highly recommend looking at the source code of the OpenStack Neutron project, which implements this functionality in a full-featured manner.